Sentence Transformers
I recently created a Python backend utilising the SentenceTransformers library to perform various tasks, such as retrieval of similar questions, and summarisation of text into a predefined number of sentences. In this article, I aim to give an overview of sentence transformers, how they differ from standard transformers, and how I utilise sentence transformers along with cosine similarity to determine the semantic similarity of sentences. An explanation of how these can be used for a variety of use cases is also given.
What are transformers?
Transformers are a relatively recent neural network architecture designed for processing sequential data, such as natural language or time series data. They were first introduced in the 2017 paper Attention Is All You Need. Prior to transformers being discovered, Recurrent Neural Networks (RNNs) were used to compute sequential data, which process data sequentially, rather than simultaneously. RNNs contain a hidden state relating to the input at the current time step and the hidden state from the previous time step, allowing them to capture dependencies over time. Despite this, RNNs struggle to learn long term dependencies, crucial for tasks such as language translation. The sequential nature of processing is not particularly scalable, making training slow. RNNs also have issues with vanishing and exploding gradients during backpropagation, which can be mitigated using LSTMs and gradient clipping at the expense of further computational complexity.
However, transformers serve to solve many of these issues using a different architecture. Transformers use self attention, which through the computation of an attention matrix, capture the relationships between tokens independent of their order. Thus, transformers are capable of parallel processing, making computations much faster. This parallel processing also allows for the use of TPUs and GPUs for matrix multiplication, making training orders of magnitude faster and more efficient. Due to the attention matrix, transformers do not suffer from the same problem of dependence on sequence length for capturing relationships between tokens. Since their discovery, a variety of transformer models have been created, such as BERT, GPT, and T5. For more information on how transformers work, I highly recommend reading the research paper linked above.
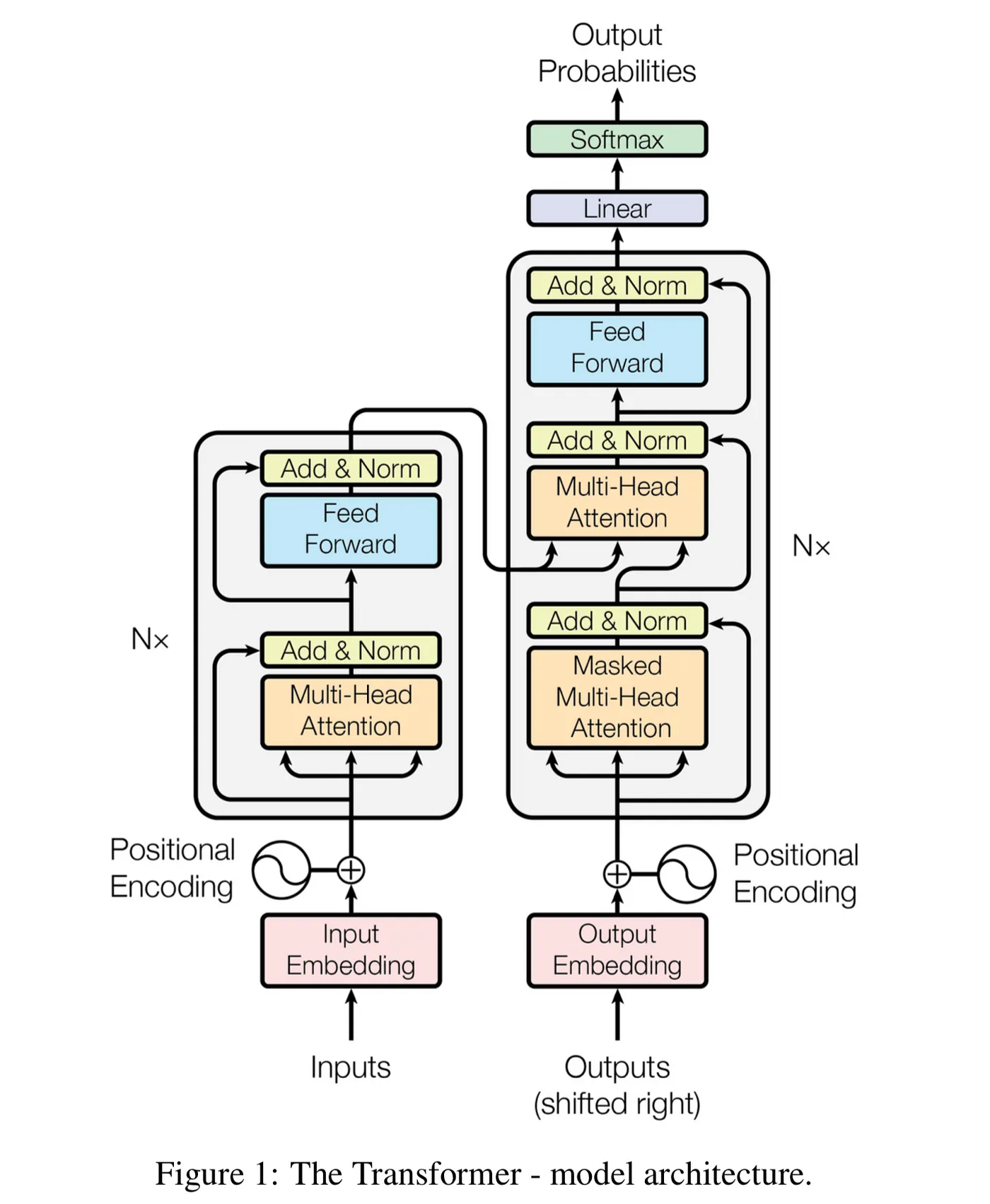
How sentence transformers differ from standard transformers
For some specific use cases, such as clustering and semantic search, sentence transformers offer an improvement over standard transformers. Unlike standard transformers, which create token level embeddings, sentence transformers create one set of embeddings for each sentence, optimised for sentence level meaning. As embeddings are simply a representation of the sentence in vector space, one can determine the similarity by calculating the cosine similarity. Note that cosine similarity is preferred over the dot product, as the former is independent of vector magnitude, considering only direction.
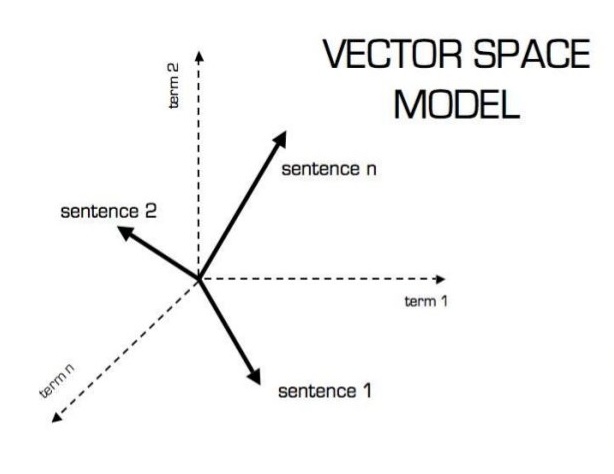
This is a marked improvement over standard transformers, such as BERT. To use BERT for the same task would prove significantly more troublesome. Firstly, BERT would require (for a similarity calculation of two sentences) that both sentences are passed to the model together, as embeddings of tokens are influenced by their surrounding context. BERT is not designed to create semantically meaningful sentence embeddings, so the context of both sentences is required to determine their relationship to each other. A further fully connected classification layer would be required. In contrast, passing sentences to SBERT (a sentence transformers model) results in a reusable embedding for each sentence, with each embedding unaffected by the other sentences. SBERT is specifically designed to represent similar sentences more closely in vector space. As a result, only cosine similarity needs to be calculated to determine the semantic similarity of two sentences.
My app
My app is a Python app, utilising FastAPI, the SentenceTransformers library, and asyncio to implement concurrent processing of requests. I also used some source code from the LexRank library (the current version has an issue with the required function not being accessible).
Embeddings creation
The first step was to create the embeddings. I initially had issues doing this due to memory leaks when using GPU on MacOS with Apple chip architecture - an issue I have long mentioned on the Apple Developer Forums. These issues have often been reported, and are likely due to the Metal plugin used by Tensorflow and Pytorch used on MacOS. As of yet, no fix has been found. Therefore, I completed all training on a Vertex AI workbench instance. In the static functions I created within the Strategy classes, the number of texts to include in each batch passed to the model can be specified to prevent OOM errors as an attempt to mitigate the memory leaks on MacOS. Notwithstanding this, using sentence transformers makes creating embeddings a breeze. It is necessary to instantiate a model, and then simply pass in the sentences to the model. A simple example is:
from sentence_transformers import SentenceTransformer
MODEL_NAME = "all-MiniLM-L6-v2"
sentences = ['Hello, here is a sentence', 'hello, here is another sentence']
model = SentenceTransformer('model-name')
embeddings = model.encode(sentences, show_progress_bar=True)
Storage of embeddings
I chose to use the h5 format to store the embeddings, due to it being ideal to store and access large quantities of data. As each file of embeddings amounted to ~1GB when stored as a h5 file, using other formats such as csv could prove to be inefficient. It is also possible to read only part of a h5 dataset at a time - useful for devices with low memory availability. For larger scale deployments, where embeddings need to be queried frequently or based on specific criteria, it may be prudent to use vector databases. As the computation of embeddings is both expensive and time consuming, I set up a Google Cloud storage bucket from which the embeddings are downloaded, with computation on device occuring as a fallback, or by manually calling the relevant static function.
Asyncio
As my first non-basic Python backend, I was unfamiliar with asyncio. Asyncio is a library for enabling concurrent operations to occur, usually in a single thread using an event loop. However, running blocking operations (such as non asynchronous computations) will still block the event loop, thereby blocking the entire backend. Thus, I opted to run expensive operations by creating new threads using asyncio. As libraries written in C/C++ (with Python bindings) release the GIL, creating a new thread allows the main thread to be unblocked, and the event loop can remain responsive to other tasks. Creating new threads does introduce new overhead, and this may need to be addressed if the program was scaled up.
Use of the app
To view the source code, or set up the application to run on your machine, see the GitHub repository. It is strongly recommended to use Conda to install dependencies, due to some libraries having native dependencies, which pip cannot manage well. A platform independent dependency yml file is given. An (fast) internet connection is recommended to download the embeddings, although creation of embeddings can be performed locally. The app has several functions (for details on how to use these, see the GitHub repo).
Text summarisation strategy
When given some text, and a number of sentences the answer should have, this strategy will choose the sentence(s) most important to the meaning of the text and return it (them). Once embeddings have been created using a sentence transformer, the degree centrality algorithm is used to determine the importance of each sentence in the context of the entire text, which are subsequently ranked and returned as appropriate. An example input is:
POST http://0.0.0.0:8000/nlp/summarise-text
Content-Type: application/json
{
"text": "There will be no extra NHS funding without reform, Sir Keir Starmer says, as he promised to draw up a new 10-year plan for the health service. The pledge came after a damning report warned the NHS in England was in a \"critical condition\". The prime minister said the new plan, expected to be published in the spring, would be the \"the biggest reimagining of the NHS\" since it was formed.",
"n_answers": 1
}
The output for this example was:
[
"The prime minister said the new plan, expected to be published in the spring, would be the \"the biggest reimagining of the NHS\" since it was formed."
]
Question and answer retrieval strategy
The text for this strategy was sourced from the SimpleWiki database. Given a question, the strategy will compute embeddings of the question, and using cosine similarity, find the most semantically similar answers to the question. A score is also given, giving a representation of how similar the question and answer are. Use cases for this type of system are when search functionality is required, such as on Quora, search engines, or Wikipedia. An example input is:
POST http://0.0.0.0:8000/nlp/question-answer-retrieval
Content-Type: application/json
{
"text": "What is the capital of China?",
"n_answers": 6
}
Which gave an output of (partially redacted for conciseness):
[
{
"title": "Beijing",
"answer": "Beijing is the capital of the People's Republic of China. The city used to be known as Peking. It is in the northern and eastern parts of the country. It is the world's most populous capital city.",
"score": "0.699"
},
{
"title": "China, Texas",
"answer": "China is a city in the U.S. state of Texas.",
"score": "0.640"
},
...
]
Quora autocomplete strategy
As the name suggests, this strategy uses a database of questions Quora released as part of a software competition. Given a question, the strategy returns semantically similar questions, along with a score for how similar each question is to the original. An example input is:
POST http://0.0.0.0:8000/nlp/quora-autocomplete
Content-Type: application/json
{
"text": "What's the biggest city in the world?",
"n_answers": 5
}
Which gave an output of (partially redacted for conciseness):
[
{
"question": "Which is biggest city in the world?",
"score": "0.978"
},
{
"question": "What's the world's largest city?",
"score": "0.970"
},
{
"question": "Which is the largest city in the world?",
"score": "0.961"
},
...
]
Conclusion
In this article, the concept of sentence transformers and their applications in natural language processing tasks was explored. We discussed how sentence transformers differ from standard transformers by creating sentence-level embeddings, which are optimised for tasks such as clustering and semantic search. We also covered the implementation details of a Python backend that utilizes the SentenceTransformers library, including the storage of embeddings, the use of asyncio for concurrent processing, and the practical considerations for deploying such a system.
The use of sentence transformers has proven to be a powerful and versatile approach for various NLP tasks, offering significant improvements over traditional methods. By leveraging pre-trained models and efficient storage formats, high performance and scalability in real-world applications can be achieved.
Building this backend system has been an invaluable learning experience, especially in understanding the intricacies of backend development and Google's cloud technologies. As a frontend developer, this project has broadened my skill set and provided insights into the full-stack development process.
I hope this article has provided a clear understanding of sentence transformers and the decisions made during the development of this application. I look forward to sharing more projects and insights in the future, including my current work on a chess app built with Lit.